首先我们得要知道robots文件时干什么的?存放的位置在哪里?
robots文件主要是告诉搜素引擎,网站哪些页面可以抓取,哪些页面拒绝抓取,下面我们看下几个截图!
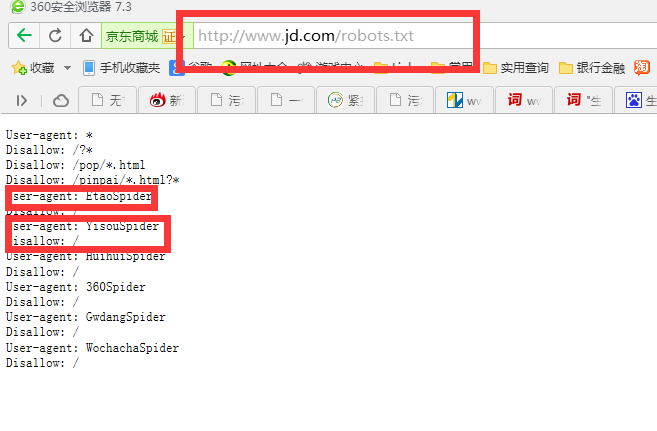
京东牛B吧,拒绝了360,一淘网,
disallow的主要作用是拒绝某些指定的搜索引擎抓取我们不想让他看见的页面,作为企业站的我们肯定是希望搜索引擎来抓取我们那么这个disallow到底有什么具体应用呢,其实我们可以用disallow拒绝404错误的地址页面或者重复的页面!
User-agent: * (声明禁止所有的搜索引擎抓取以下内容)
Disallow:/blog/(禁止网站blog栏目下所有的页面。比如说:/blog/123.html)
Disallow:/api(比如说:/apifsdfds/123.html也会被屏蔽。)
Disallow:*?*(只要你的路径里面带有问号的路径,那么这条路径将会被屏蔽。比如说:http://xxxxx/?expert/default.html将会被屏蔽。)
Disallow:/*.php$(意思是以.php结尾的路径全部屏蔽掉。)
Sitemap:http://xxx.com/sitemap.html 网站地图 告诉爬虫这个页面是网站地图
User-agent: * 允许访问所有
Disallow: / 拒绝所有
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
更多搜索引擎体验请点击
下一篇:如何打造一个搜索引擎体验好的网站